理解R-CNN
最近需要使用目标检测对表格内容提取,故决定将该领域的学习以博客的形式记录下来。这是系列文章的第一部分,主要介绍R-CNN的模型结构,特别是弄懂论文中如何训练R-CNN。本文参考了几篇优秀的文章,如果感兴趣尽可以跳到最后阅读原文。
1. 简介
本文将要介绍的是2014年来自UC Berkeley的一篇论文《Rich feature hierarchies for accurate object detection and semantic segmentation》。论文摒弃传统手工提取特征的做法,转而使用CNN架构提取图像特征。虽然现在看来,R-CNN的架构有一定的不足,但是引入CNN的做法使得目标检测领域有了新的研究方向。
下面我将尽可能简略地介绍R-CNN的思想以及其训练过程。在介绍开始前,我会假设您对DNN、CNN以及分类任务和目标检测任务已经有一定的了解。
2. 模型介绍
R-CNN的运作方式如下:
- 输入一张完整的图片;
- 从中提取大约2000个region proposals;
- 将这些提取出来的region proposals送入CNN提取特征;
- 将CNN转化得到的特征送入线性分类器SVM中进行分类。
下图是论文中给出的示意图:
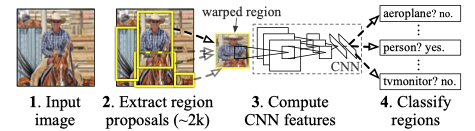
R-CNN最值得称赞的地方无疑是采用region proposals加上CNN进一步提取特征。
2.1. 提取Region Proposals
我们需要一些算法去提取Region。算法的输入是一张图片,输出是若干个可能包含目标物体的区域,比如可以使<$c_x, c_y, H, W$>表示一个提取出的区域,前两个变量是Anchor Box的位置坐标,后两个变量是其高度与宽度。
初步得到的候选区域非常的noisy,它们中可能确实包含需要被检测的object,可能也没有。同时,输出的<$c_x, c_y, H, W$>也不一定准确,如下图是一张图片中提取出的若干Region Proposals,其中绿色框可以被认为是我们期待输出的Anchor Box,而蓝色框则是有缺陷的。
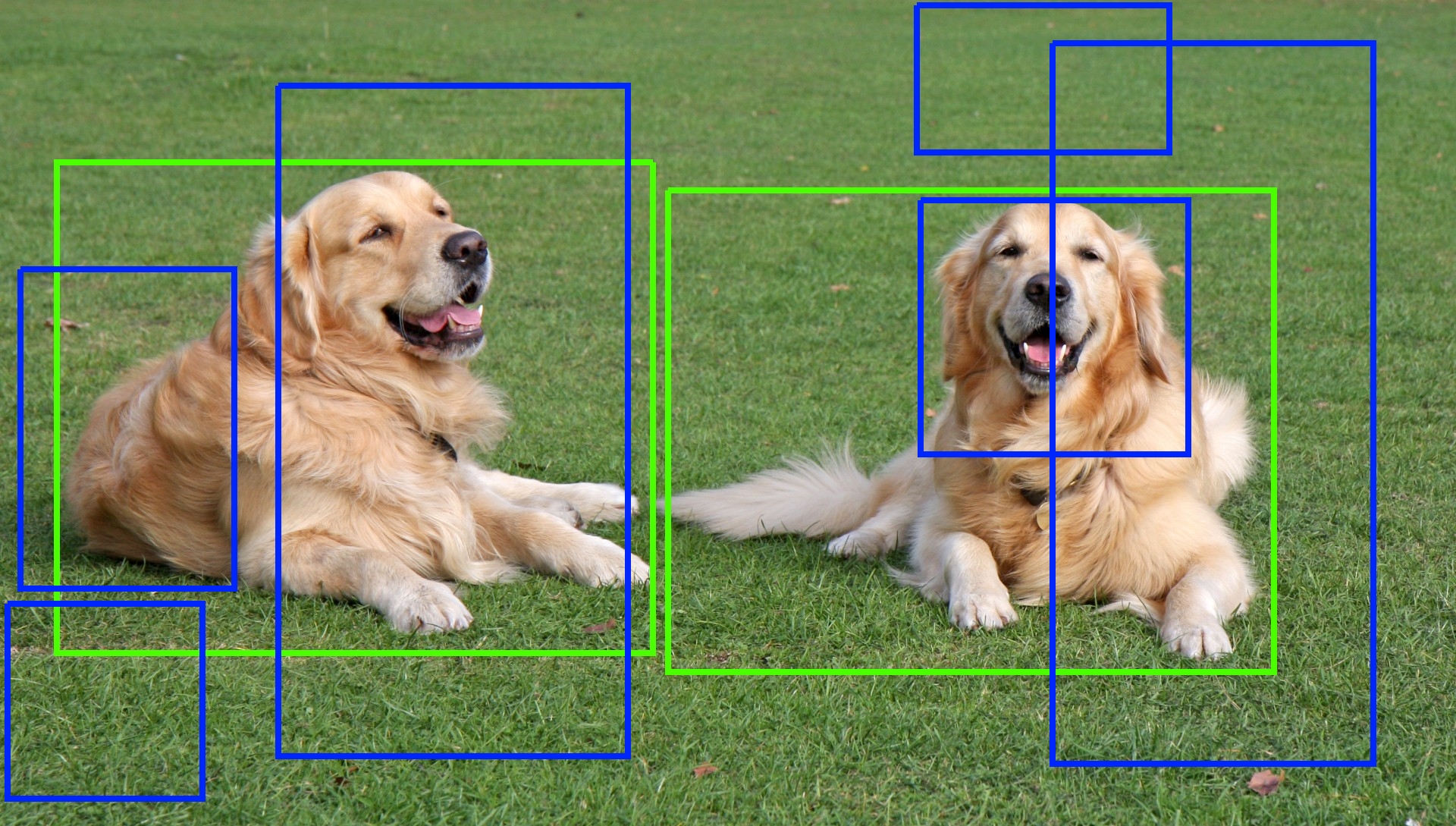
Region proposal algorithms算法基于颜色、纹理等对一张图片进行切割,使得一些近似的区域连接在一起产生Region。Selective Search是其中的一种,也是被应用在论文中的算法。更具体的内容,本文不再阐述,有兴趣的读者可以访问文章,有着非常详尽的介绍,并且给出了相应的实现代码。
2.2. CNN
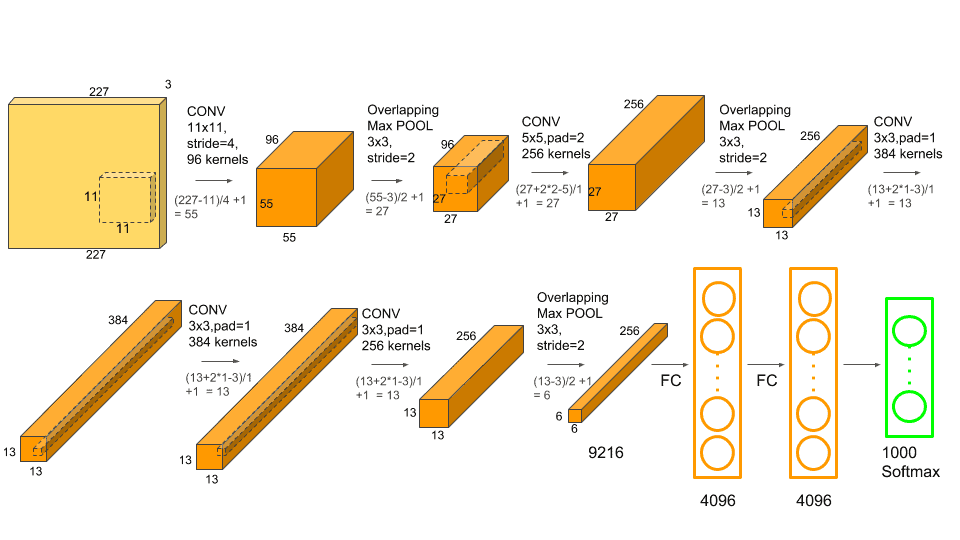
在得到Region proposals后,将每一个区域送到CNN架构中,得到该区域的特征向量,在论文中使用的CNN是AlexNet。
第一个问题来了,这部分CNN需要怎么样被训练?因为模型后接的是若干个SVM分类器,显然两者无法一起训练。
论文中的做法是对CNN部分进行预训练,具体训练这部分的参数将在之后介绍。在AlexNet的模型确定之后,将其最后一层去掉,也就是说,通过CNN后,之前的Region proposals被转化至4096维的向量。
另外一个问题是,AlexNet的输入是固定的,即(227, 227, 3),而之前提取出的Region proposals形状不一,如何输入AlexNet?这就需要对每个Region进行resize的操作。
2.3. SVM
在获得特征向量后,下一步是将其送入若干个SVM分类器中。比如,目标检测的对象有10类,那么总共要送入10个SVM分类器。
2.4. 修正Anchor Box
到上一步为止,R-CNN的预测流程已经走完了一大半。最后还有一个环节就是确定目标所在的位置,即确定<$c_x, c_y, H, W$>。
之前在提取候选区域的时候,已经有一个初步的<$c_x, c_y, H, W$>$_{prior}$,接下来便是对已经确实是目标的region进行修正。关于修正的算法,本质上利用一个回归器进行拟合。
这样,我们便走完了R-CNN的全部流程。
3. R-CNN的训练
在这一小节,我将主要介绍如R-CNN的训练过程。R-CNN的一个重大缺陷就在于它不是端到端的,无法把所有的组件合并到一个pipeline一起训练参数。论文中的解决办法是分开训练,下面具体展开介绍。
CNN部分,论文使用预训练方式确定网络参数。首先,使用选定的网络架构(本例是AlexNet)在数据集ILSVRC 2012 classification dataset进行训练。该数据集中包含1000个不同类别的图片,彼时的任务是多分类。
在上个任务训练结束后,将训练好的网络用于另一个任务的训练,即使用PASCAL VOC dataset或ILSVRC 2013 detection dataset进行fine-tuning。上一个任务是涉及1000个类别的多分类,在这个任务中,将之前CNN的最后一层去掉,加上新的一层,对N+1种类别分类,此处的N是数据集中的类别个数。
同时,网络的输入也有所变化。在pre-training阶段的输入是整张图片,在fine-tuning阶段,输入则是warped region proposals,即筛选出的2000个左右的候选区域。这就需要重新构建用于训练的数据集,将候选区域与ground-truth bounding box计算得到的IOU > 0.5的视为正例,反之视为负例(即预测出来为背景)。还有一些训练的参数设置,这里不过多阐述,感兴趣的可以查看论文。
最后,SVM部分考虑使用简单的二分类。比如检测region proposal是否含有车辆,有车的被视为正例,无车的被视为负例。问题主要在于,如果判定region proposal是否包含正例,论文以IOU=0.3为界限,这是通过验证集得出的值。
分类部分的训练大致如上所述,还有一个回归器需要训练,用于对Anchor Box的修正,论文使用的修正模型是Ridge Regression。训练得到参数后,将<$c_x, c_y, H, W$>$_{prior}$以一定方式转化到<$c_x, c_y, H, W$>。
4. 总结
本文主要对R-CNN进行了简单的介绍,包括其预测流程以及训练流程。对于其中一些细节并没有过多的深入,因为本人认为R-CNN在2020年看来确实有些“老”,主要的缺陷集中在训练和预测速度慢,无法端到端训练等。预测时首先要提取多个region proposals,接下来对于每一个region proposal转化得到的特征向量,在分类阶段还需要送入若干个二分类SVM,整体的效率大打折扣。
但是其中的一些训练思想是很值得借鉴的,先使用pre-traing,再使用fine-tuing已经是当前网络训练的基本操作。同时,整篇论文逻辑清晰,简单易懂,是很好的文章。
Reference
- https://arxiv.org/pdf/1311.2524.pdf ,R-CNN论文
- https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/ ,介绍Selective Search
- https://medium.com/@selfouly/r-cnn-3a9beddfd55a ,介绍R-CNN
- https://www.mihaileric.com/posts/object-detection-with-rcnn/ ,介绍R-CNN
- https://www.jianshu.com/p/9bcbf6d98238 ,介绍R-CNN,中文