Spelling Error Correction with Soft-Masked BERT
Recently, I want to learn how to build a knowledge graph. In the period, I realize that
spelling error correctionis one of the most important links. So, I should find a paper, do some reading and take notes about it.
Challenges
For the Spelling Error Correction for Chinese Character, there are mainly two challenges, displayed as follow:
- First, some mistaken is produces by written. E.g. :
- Wrong: 埃及有金子塔。Egypt has golden towers.
- Correct: 埃及有金字塔。Egypt has pyramids.
- For this condition, we could correct it with the
world knowledge.
- Another situation occurs when we need to correct it with
inference. E.g:- Wrong: 他的求胜欲很强,为了越狱在挖洞。 He has a strong desire to win and is digging for prison breaks
- Correct: 他的求生欲很强,为了越狱在挖洞。 He has a strong desire to survive and is digging for prison breaks.
Past Methods
It exists mainly two categories methods, namely traditional machine learning and deep learning.
Some methods are displayed as below:
- a unified framework, which is consists of a pipeline of error detection, candidate generation and final candidate selection by traditional machine learning.
- a
Seq2Seqmodel with copy mechanism which transforms an input sentence into a new sentence with spelling errors corrected. - Bert based model. The dataset to fine-tuning the Bert can be generated by
a large confusion table. In the inference period, Bert predict the most probability character for each position.
In the above methods, we can get awesome accuracy with Bert. However, it seems that the result could be better with some change. In the origin bert, the model randomly select 15% words to mask, which results the model only learn the distribution of masked token and choose not to make any correction.
Proposed method
The proposed method in this paper is also Bert based. To address the aforementioned issue, the proposed model contains two network, which is detection network and another is correction network.
Below is the architecture of proposed model: Soft-Masked BERT
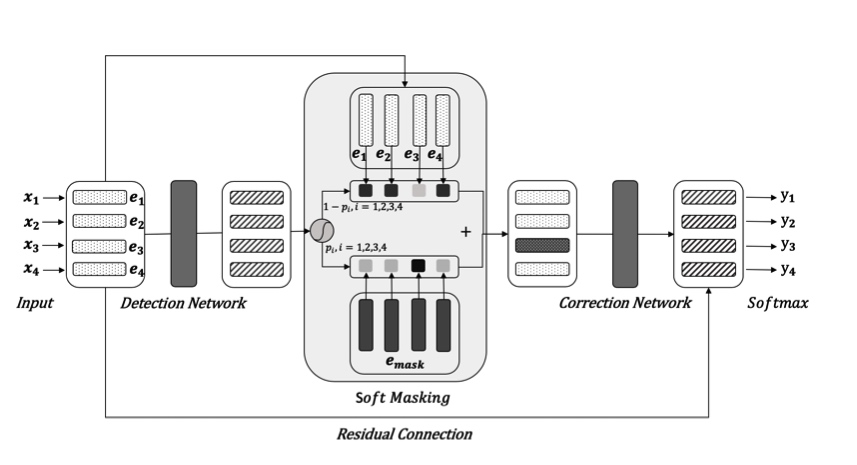
As the figure illustrates, the model mainly contains two network. The correction network is a Bi-GRU network that predicts the probability whether the character is error for each position. And the correction network is the same as former Bert.
Next, we’ll dive into the detail of training method of the Soft-Masked BERT.
- Firstly, we should creates an embedding for each character in the input sentence, which is referred as the
input embedding. - Next, we send the input embedding to
detection networkand get the output of probability of errors for the character in each position. - Now, we have the probability indicating whether it’s error in each position. We do weighted sum for the
input embeddingand[MASK] embeddingby the error probabilities.- To explain clearly, we can look the
architecture illustrationabove. We take the3rd positionfor the example. - With the detection network, we get the error probability of this position, denoted as $p_3$, which indicates how much the character in this position would be error. Therefore, the correct probability of the position is $1 - p_3$.
- Meanwhile, we have the embedding of the
3rd position characterand[MASK] token. So we can do weighted sum for these two embedding, and the weight is just the $p_3$ and $1 - p_3$.
- To explain clearly, we can look the
- Use the output of detection model as the input of the next correction model.
- There is also a residual connection between the input embedding and the output of correction model. The combination of them will be sent to the softmax layer to predict the max probability of the character, which should be put on this position.
Training
This model is training end-to-end, although it contains two sub-model.
And the objective function for these two task are both cross entropy. To learning on a better way, this paper use a coefficient to combine these two loss, which is described as below:
\begin{equation}
\boldsymbol \ell_{total} = \lambda \cdot \boldsymbol \ell_{c}+(1-\lambda) \cdot \boldsymbol \ell_{d}
\end{equation}
where $\boldsymbol \ell_d$ is the objective for training of the detection network, and $\boldsymbol \ell_c$ is the objective for training of the correction network, which is also the final decision, and $\lambda$ is the coefficient.
Reference
- https://arxiv.org/abs/2005.07421, origin paper